Artificial intelligence has been a longstanding pursuit in the field of computer science, driven by the ultimate goal of creating machines capable of human-like intelligence. At its core, this endeavor aims to empower computers with the ability to solve a wide range of problems, from answering general questions to proving theorems, writing code, creating art, and playing games. This ability to solve a large variety of arbitrary problems may be referred to as general intelligence.
The field of artificial intelligence has come a long way. Today, it is spearheaded by neural networks and machine learning techniques, which have been responsible for realizing many of the goals envisioned over the last century. We now have models capable of unprecedent super-human performance in complex game environments, such as AlphaGo [1, 2]. We also have models capable of creating a images and illustrations from textual descriptions alone, such as DALL-E [3, 4] and Stable Diffusion [5]. Most notably, we have models that are able to interact with humans using natural language and solve an impressive number of tasks, as exemplified by ChatGPT [6, 7, 8].
Indeed, large language models (LLMs) like ChatGPT are prime examples of what modern neural networks are capable of. Through extensive self-supervised pretraining and instruction-following fine-tuning, these models are able to achieve remarkable feats of intelligence. These include not only holding conversations in natural language, but also generating code, solving mathematical problems, composing and editing text, and providing translations between languages. Arguably, this is the closest we have ever been to having a system capable of general intelligence.
But can these models ever reason like a human? Despite their impressive abilities, these models are not infallible; they fall short of consistent generalization in many tasks. In fact, they occasionally make simple reasoning mistakes that a human would easily avoid. This raises some questions about what these models are ultimately capable of doing. Let’s disregard the question of learning for a moment and focus strictly on their theoretical capabilities. Could these models solve any problem that a human could solve? Exactly how powerful are they? And, perhaps most importantly, is there a systematic way to go about such questions?
In this article, we will attempt to answer these questions, unraveling the capabilities and limitations of contemporary neural network models. In doing so, we will hopefully shed light onto some of the challenges and potential solutions in the pursuit of general intelligence using neural networks.
Theory of computation
The theory of computation is a branch of theoretical computer science that explores the fundamental principles of computation, encompassing the study of algorithms, computational problems, and formal computational models. Using this theory, we are able to analyze the capabilities of different models of computation, establish the computational complexity of different problems in terms of space and time, and even determine whether a problem is computable at all. To enable this, the theory of computation offers a wide range of formal tools, including automata, formal languages, grammars, logics, and circuits.
There are many different models of computation within this theory, each with their own set of capabilities and some stronger than others. A particularly important one is the Turing machine, which is capable of performing any algorithmic computation. According to the Church-Turing thesis, any function that is computable can be computed by a Turing machine. Thus, any model that can simulate a Turing machine is equally capable of universal computation. Such models are said to be Turing-complete.
Knowing this, it would be natural to expect that a computational model that can perform arbitrary reasoning and solve arbitrary problems must be capable of performing arbitrary computation. In other words for a model to be capable of general intelligence, it must be capable of universal computation (Turing-complete).
But what does all of this have to do with neural networks? Much like any computational model, neural networks transform an input into an output through well-defined operations, and are therefore a subject of the theory of computation. Accordingly, we are able to determine the computational power of different neural network architectures based on this theory. In fact, this treatment of neural networks is not a new idea. Let’s explore this further.
Neural networks and their computational power: the beginnings
The study of neural networks has a perhaps surprising relationship with the field of theoretical computer science [9]. This relationship can be traced back to the pioneering work of McCulloch and Pitts [10], which introduced the first artificial neural network model and demonstrated its ability to express logical propositions, and to Kleene [11] and Minsky [12], who established the computational model of finite automata and its connection to artificial neural networks.
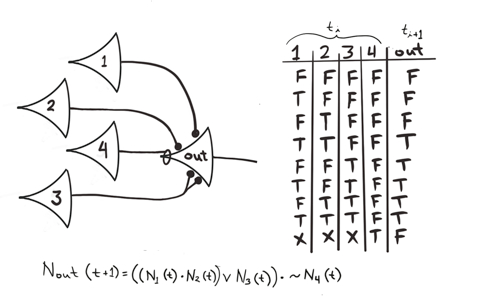
Representation of a logical proposition by a McCulloch-Pitts network [13].
In 1943, McCulloch and Pitts introduced the first computational model of biological neural networks. In this model, neurons are represented by threshold logical units (TLUs). Each unit exhibits an “all-or-nothing” behavior, where it can be considered either active or inactive based on the number of excitatory inputs and the presence of inhibitory inputs. Due to the binary nature of this model, McCulloch and Pitts argued that neural activity can be treated by means of propositional logic. Essentially, the output of each neuron in a network can be interpreted as the truth value of a logical proposition. By combining multiple neurons, we can therefore construct propositions of increasing complexity (see image above). Based on this, McCulloch and Pitts characterized the set of propositions that can be expressed by neural networks.
Later, in 1956, Kleene published a mathematical reworking of McCulloch’s paper which also included significant developments in the theory of finite automata. In his paper, titled Representation of Events in Nerve Nets and Finite Automata, Kleene characterized the set of “regular events” (which we today refer to as regular expressions), and showed that this is exactly what finite automata and McCulloch-Pitts networks with circles1 can represent. Therefore, Kleene established the equivalence between finite automata and McCulloch-Pitts networks. The simulation of finite automata using McCulloch-Pitts neurons was later explicitly shown by Minsky in 1967, in his book Computation: Infinite and Finite Machines.
Since then, neural networks have evolved significantly, incorporating continuous values, multiple layers, differentiable activations, and learning through backpropagation. This process has led to the development of the modern neural networks that we know today. Concurrently, the theory of computation has also advanced, influencing the study of the computational power of these neural networks.
The computational power of modern sequence models

Illustration of a recurrent neural network (RNN).
With the development of modern RNNs [14], researchers became increasingly interested in understanding the computational and learning abilities of sequence-processing neural networks. This has led to multiple research efforts into determining the capabilities and limitations of RNNs and their extensions, such as the LSTM and memory-augmented neural networks [15, 16, 17, 18]. Using tools from the theory of computation, including automata and formal languages, researchers have conducted empirical and theoretical analyses in order to establish what kinds of strings such networks can process and what problems they can effectively solve.
Around this time, an important line of research emerged, focusing on the theoretical investigation of the Turing completeness of neural networks. In their classical paper, Siegelmann and Sontag [19] established the Turing completeness of RNNs with arbitrary precision, saturated linear activations, and unlimited computational steps. They demonstrated this by simulating a two-stack machine, where the RNN’s (arbitrarily precise) hidden state encoded the machine’s internal state at each step. This result would influence research decades later.
However, there are limitations associated with the assumptions in Siegelmann’s work. Several authors have argued that these are unrealistic, leaving a significant gap between theory and practice [20, 21, 22]. Notably, the Turing machine simulation proposed in her proof would be difficult to realize in a practical learning setting and substantially differs from the typical supervised sequence modeling setup. Thus, a more recent line of research attempts to study the computational power of neural networks under more realistic assumptions, such as finite precision and a number of computation steps bounded by the input length.
| Level | Task | RNN | LSTM | Stack-RNN | Tape-RNN | Transformer (encoder) | Transformer (autoregressive) |
|---|---|---|---|---|---|---|---|
| R | Even Pairs | 100.0 | 100.0 | 100.0 | 100.0 | 96.4 | - |
| R | Modular Arithmetic (Simple) | 100.0 | 100.0 | 100.0 | 100.0 | 24.2 | - |
| R | Parity Check | 100.0 | 100.0 | 100.0 | 100.0 | 52.0 | - |
| R | Cycle Navigation | 100.0 | 100.0 | 100.0 | 100.0 | 61.9 | - |
| DCF | Stack Manipulation | 56.0 | 59.1 | 100.0 | 100.0 | 57.5 | 53.2 |
| DCF | Reverse String | 62.0 | 60.9 | 100.0 | 100.0 | 62.3 | 53.5 |
| DCF | Modular Arithmetic | 41.3 | 59.2 | 96.1 | 95.4 | 32.5 | - |
| DCF | Solve Equation | 51.0 | 67.8 | 56.2 | 64.4 | 25.7 | - |
| CS | Duplicate String | 50.3 | 57.6 | 52.8 | 100.0 | 52.8 | 100.0 |
| CS | Missing Duplicate | 52.3 | 54.3 | 55.2 | 100.0 | 56.4 | - |
| CS | Odds First | 51.0 | 55.6 | 51.9 | 100.0 | 52.8 | 54.7 |
| CS | Binary Addition | 50.3 | 55.5 | 52.7 | 100.0 | 54.3 | 69.0 |
| CS | Binary Multiplication | 50.0 | 53.1 | 52.7 | 58.5 | 52.2 | 52.2 |
| CS | Compute Sqrt | 54.3 | 57.5 | 56.5 | 57.8 | 52.4 | 52.4 |
| CS | Bucket Sort | 27.9 | 99.3 | 78.1 | 70.7 | 91.9 | 40.4 |
Maximum accuracy in recognizing different formal languages across the Chomsky hierarchy (R = Regular, DCF = deterministic context-free, CS = context-sensitive) [23].

Correspondence between formal languages, automatons, and different neural network architectures [23].
This trend has been followed by many recent works, both empirical and theoretical, which investigate the computational power of sequence models in practical settings [21, 22, 24, 25, 26, 27]. Some of these works not only explore the models’ expressive capacity, but also their ability to learn to recognize languages in practice. One particularly relevant example is the recent work by Delétang et al. [23], which empirically examines the ability of various neural network architectures, including RNNs, LSTMs, Transformers, and memory-augmented neural networks, to learn how to recognize different formal languages (see table above).
To accomplish this, the researchers trained each model using a variety of short strings from each formal language. Then, they evaluated the generalization ability of the models by measuring their accuracy on a diverse range of test strings, many considerably longer than those seen during training. Based on these results, the authors classified each architecture according to the Chomsky hierarchy (see image above). Notice how memory-augmented neural networks exhibit a stronger capacity compared to the other architectures, and how Transformers seemingly do not correspond to any level of the Chomsky hierarchy.
| Neural Network Architecture | Recognizable Languages | References |
|---|---|---|
| Sigmoid / Tanh RNN | Regular languages | [18, 22] |
| LSTM | Regular languages + Counter languages | [21, 22] |
| GRU | Regular languages | [22] |
| CNN (finite receptive field) | Strictly local languages | [22] |
Common neural network architectures and the formal language classes they can theoretically recognize.
Within this context, Merrill [22, 28] made a theoretical advance by formalizing the concept of saturated neural networks. In these networks, activation values are discretized by increasing the parameter norm to an asymptotic limit in the presence of squashing activation functions, similarly to the idea described in [18]. The concept of saturated neural networks enabled a principled analysis of neural sequence models that led to a more realistic classification of their computational capabilities. The table above presents some of the most relevant theoretical results related to this line of research.
The computational power of Transformers
The Transformer architecture [29].
So far, much of the results we have seen focused on recurrent neural networks. But the most prominent architecture in today’s sequence processing landscape is the Transformer, which is the basis of models like ChatGPT and other LLMs. Due to the relatively recent emergence of this architecture [30], research into the theory of Transformers and their attention mechanism is comparably new in relation to that of RNNs. Nonetheless, many recent studies have aimed at theoretically analyzing them.
Inspired by Siegelmann’s work [19], Pérez et al. [31, 32] proved the Turing completeness of Transformers. The proof consisted in directly simulating a Turing machine, step by step, using an encoder-decoder Transformer. In the proposed simulation, the output tokens are responsible for keeping track of the machine’s state and current symbol at each time step. In each forward pass, the decoder calculates the current position of the Turing machine’s head by summing the directions of all previous head movements (i.e., $\lbrace +1,-1 \rbrace$), which are in turn calculated from the previous output tokens. Then, it retrieves the symbol corresponding to the calculated position and proceeds to output the next state and the next symbol under the head. This process is repeated until halting. Similarly to Siegelmann and Sontag [19], the authors assumed arbitrary precision and an unlimited number of computation steps.
Contrasting with Pérez’s approach, another line of research analyzed Transformers from a different perspective. In particular, this line of research focuses on the ability of Transformer encoders to process strings in a single step, as opposed to solving tasks using multiple decoder steps. In this context, the first theoretical results on the limitations of Transformers were shown by Hahn [33]. He demonstrated that hard-attention Transformers—in which each layer can only attend to a single token at a time—cannot recognize the Parity2 and Dyck-$k$3 languages, suggesting limitations on the ability of Transformers to model hierarchy. Moreover, Hahn showed that soft-attention Transformers cannot robustly model the Parity and Dyck-$k$ languages, being unable to attain perfect cross-entropy on these tasks. Particularly, this proof assumed that all layers of the Transformer are Lipschitz-continuous.
Hahn’s work laid the ground for subsequent studies. Chiang and Cholak [34] followed up by observing that the Lipschitz-continuity assumption disregarded the impact of layer normalization on the Transformer. Based on this observation, the authors constructed a soft-attention Transformer with layer normalization that can robustly recognize the Parity language. Yao et al. [35] also followed up, demonstrating that Transformers can recognize Dyck languages with bounded nesting depth. According to the authors, this setup could better represent the hierarchical structure of natural language, which could help explain the success of Transformers in natural language processing (NLP).
Meanwhile, Bhattamishra et al. [36] demonstrated that uniform-attention Transformers—in which each layer can attend to multiple tokens with uniform intensity—can recognize the Shuffle-Dyck-$k$4 language. Furthermore, they showed that Transformers can simulate a less powerful kind of counter automaton called Simplified Stateless Counter Machine (SSCM), establishing a first lower bound on the computational power of these models. They supported this observation by empirically demonstrating that Transformers can learn several regular and counter languages.
In parallel, Weiss et al. [37] introduced RASP, a programming language that closely emulates the computational constraints of the Transformer architecture, providing a first computational model of Transformers that could be useful in understanding their inner workings and learning abilities. In their work, the authors manually construct RASP programs to solve different tasks and show that these can be realized by actual models.

A Boolean circuit that takes a string in $\lbrace 0, 1 \rbrace ^5$ and returns whether it contains the bigram $11$. By constructing families of circuits (i.e., sets of related circuits parameterized by input size), we can use circuit complexity theory to analyze the computational capabilities of parallel models in processing arbitrary strings [38].
A more robust understanding of the computational model of Transformers emerged after Hao et al. [39] analyzed the architecture using circuit complexity theory. Simplifying and unifying prior results, the authors proved that hard-attention Transformers can only recognize formal languages in the complexity class $\textsf{AC}^0$, which comprises the languages recognizable by families of Boolean circuits with polynomial size constant depth. The computational power of uniform and soft-attention Transformers, however, remained an open question.
Through additional developments [38], Merrill and Sabharwal [40] finally published the paper titled The Parallelism Tradeoff: Limitations of Log-Precision Transformers. In this paper, they established that log-precision Transformers can be simulated by uniform polynomial-size constant-depth threshold circuits and, as a result, are limited to recognizing languages in $\textsf{TC}^0$, suggesting fundamental limitations on the expressive capacity of Transformers. Later, researchers further improved on these results by proving tighter bounds on the expressivity of Transformers in terms of generalizations of first-order logic [41, 42].
In summary, research suggests that the Transformer does not align with any of the major classes of the Chomsky hierarchy. Rather, results indicate that Transformers correspond to a limited parallel computational model, echoing the early idea that the attention mechanism has limited sequential processing abilities [24, 43]. In particular, Merrill and Sabharwal’s findings indicate that, under reasonable assumptions5, there are many problems for which Transformers cannot generalize. For instance, it would be impossible for an encoder-only Transformer such as BERT [44] to achieve perfect generalization on the Boolean satisfiability problem (SAT). Likewise, a similar statement can be made about decoder-only Transformers like GPT [45].
Specifically, no such an LLM would be able to correctly answer the question “Is the Boolean formula $x$ satisfiable?” for arbitrary $x$ with a simple yes-or-no answer, since that would imply a computational budget of a single step. Importantly, this limitation is not confined to the SAT problem; rather, it extends to any problem of equivalent complexity.
Are there more powerful models?
Several approaches have been adopted to overcome the limitations of conventional architectures and create more powerful models. One of them, which we have already mentioned, is memory-augmented neural networks [17, 46, 47, 48, 49, 50, 51, 52]. In general, these networks are constructed by equipping a recurrent neural network with some kind of differentiable memory, typically with the goal of emulating a stronger kind of automaton.
Another approach is based on the very observation that, while the computational budget of a neural network is often constant, some problem instances are harder than others and may thus require more computation. With this in mind, researchers have proposed several dynamic computation schemes for neural networks [43, 53, 54], which allow them to adapt the amount of computation according to the input.
However, these approaches often result in models that are complex, difficult to scale, or that do not beat Transformers on practical tasks. This raises a question: is there a simple model that is both powerful and efficient, encompassing both parallel and sequential computation? This query motivated me to start my own investigation during my undergraduate studies. Let’s briefly explore it.
One interesting line of research investigates the use of differentiable optimizers as neural network layers. The main idea is to use a parameterized optimization procedure as a part of the forward pass of a neural network and then differentiate through it such that its parameters can be learned.
Examples of this kind of model include OptNet [55], a differentiable convex optimization solver, SATNet [56], a differentiable MAXSAT solver based on semidefinte programming, and CombOptNet [57], an integer programming solver that uses gradient approximations for differentiability. Similarly, IREM [58] is a differentiable energy-based model that solves problems by minimizing an energy function using gradient descent.
By formulating the forward pass as an optimization problem, these models have a real potential for greater expressive power, often promising superior performance in reasoning problems. However, they can be difficult to use practice. In general, the optimization procedures associated with these models incur in elevated computational costs, which can quickly become prohibitive. Moreover, these models are not adapted to sequence data, which precludes their immediate use in applications such as language modeling.
In this context, a different yet related class of models captures our attention: the class of deep equilibrium models (DEQs) [59]. In essence, these models revolve around solving an equilibrium equation expressed as:
$$\bm z^\star=f(\bm z^\star,\bm x)$$
Their output is calculated by repeatedly applying a neural network layer $f(\cdot)$ until a fixed point is reached, making DEQs equivalent to infinitely deep weight-tied neural networks. As for backpropagation, these models exploit implicit differentiation in order to compute gradients by solving another equilibrium equation, without the need to store intermediate activations.
Notably, in contrast to the previously discussed models, DEQs can be readily applied to sequence data by employing convolutional and Transformer layers. In fact, they have shown positive results in several NLP benchmarks, with some studies suggesting that DEQs have superior generalization capabilities compared to standard architectures [60].
However, it is crucial to understand the abilities of these models from a theoretical perspective. Are DEQs any more expressive than regular CNNs and Transformers? Does their infinite depth lend them more computational power? The short answer is yes. I will not go into much detail, but we can show that DEQs can simulate formalisms ranging from finite automata to Turing machines, depending on the assumptions made.
For the Turing machine simulation, the key is to imagine that the vector $\bm z$ represents the tape, where each position encodes a symbol, a state, and the presence of the head. Then, at each step, we only need to update the current symbol and state and then move the head to one of the neighboring positions, which can be easily done with convolution operations.
Unfortunately, these results do not necessarily translate well to practice. For instance, running the experiments from Delétang’s work [23] will show that DEQ-CNNs fail to learn even the most basic regular languages. Moreover, DEQs are quite inefficient compared to regular sequence models, which can render them unusable on longer sequences.
The bottom line is that computational efficiency seems to be a major issue among all these approaches. It appears that there exists, in fact, a parallelism tradeoff, and that it is key to the efficiency and success of Transformers; and it seems that any attempt at a more powerful neural network architecture inevitably leads to complications.
What now?
We started this article on a quest to understand the reasoning and universal computation abilities of neural networks. Particularly, we have focused on the computational power of Transformers, the architecture that powers most current LLMs. Research on the subject, however, reveals that the computations that these models can perform in a single step are quite limited, and that there are many problems that they cannot solve. Unfortunately, alternative architectures that might offer greater computational capabilities often come with a variety of drawbacks such as elevated computational costs, making them impractical choices for creating models capable of general intelligence.
But what if we give up on the idea of having a model with an “all-powerful” step and fully embrace the idea of solving problems through multiple explicit “weak” steps? After all, this is the approach used in Pérez’s paper in order to prove the Turing completeness of Transformers. This is also what the “step-by-step thinking” strategy [61, 62], widely used by LLMs, looks like. Is this ultimately the right approach to problem-solving? If so, are Transformer-based LLMs already capable of universal computation, meaning that they are all we need to achieve general intelligence? Let’s discuss this further.
Let’s start by going back to Pérez’s work. In order to see if his Turing completeness proof holds in practice, we must go over its assumptions. The two main ones are unbounded computation and arbitrary precision. Let’s ignore the assumption of an unlimited number of computation steps, since that is precisely what we’re aiming for—taking as many steps as necessary in order to solve a problem. Let’s also ignore the arbitrary precision assumption, this time on the basis that the floating-point numbers on the computer are precise enough to carry Turing-complete computation for all practical problems (in fact, some believe that log-precision Transformers have enough capacity to compute a Turing machine step).
Given this context, does Pérez’s proof apply in practice? Not necessarily. This is because the construction proposed by Pérez relies on a non-standard attention score function and an unconventional positional encoding scheme. Meanwhile, practical Transformers use dot-product attention and standard positional encoding schemes, which would likely render the attention patterns needed for the Turing machine simulation impossible. In the end, I believe that the practical computational power of autoregressive Transformer decoders is still not entirely clear.
However, even if such Transformers were proven to be Turing-complete in practice, a critical problem would remain: these models have linear space complexity and quadratic time complexity. Because of this, processing excessively long sequences becomes impractical. Certainly, such models are not able to naively reason for an indefinite amount of time, nor are they able to solve problems with very long descriptions. As an example, fixing a bug in a program with 10K lines of code can be unfeasible even for the largest commercial LLMs of today. Furthermore, while the attention operation is “dense” (i.e., the computation is performed over all input elements), the memory access pattern required to simulate a Turing machine should be mostly sparse.
In Pérez’s simulation, after computing the current head position, we should only need to retrieve the current and the next element under the head. Similarly, in a practical setting, we can imagine that the sparsity of an LLM’s attention increases as its context gets longer through interaction. This phenomenon arises as a simple result of the increasing amount of irrelevant information in its history over time. From this, we can conclude that there is an inherent inefficiency in the way (dense) attention works.
In contrast, an ideal model should have a constant computation cost per step and sparse-access memory at inference time. This is akin to the construction proposed in a recent paper by Chung and Siegelmann [63], in which they construct a Turing-complete finite-precision RNN that is augmented with two external growing memory modules so as to simulate a two-stack machine. However, the RNN in this construction interacts with the memory modules in a discrete, non-differentiable manner, meaning that alternative learning strategies are necessary in order to train the model in practice (e.g., reinforcement learning). Moreover, since the model is RNN-based, it cannot be parallelized during training like Transformers.
Yet, efficiency during training is just as important as efficiency during inference. After all, large-scale self-supervised pretraining is the cornerstone of building LLMs. Fortunately, a recent yet rapidly evolving line of research aims to develop efficient alternatives to Transformers while matching their performance levels [64, 65, 66, 67, 68, 69, 70]. Particularly, this line of research has produced several state-space models that can be both trained in parallel and run recurrently at inference time. With remarkable constant complexity both in space and time during inference, these models have exhibited promising results across a multitude of sequence processing tasks, both real and artificial. Notably, there have been good results on both language modeling and downstream NLP tasks.
However, it should be noted that these models are based on linear recurrences, in contrast to the nonlinear recurrences of traditional RNNs. The expressive power of such networks remains unknown, although it is likely weaker than that of Transformers.
A path forward?
Using these recent architectures, it might be possible to create a model that is both Turing-complete and capable of efficient parallel and sequential computation. The key is to equip the model with an external memory module and use the right training setup. Specifically, this training setup would consist of two distinct phases. In the first phase, the model goes through parallel self-supervised pretraining, during which it learns from a substantial amount of text. In the second, the model is subjected to sequential reinforcement learning fine-tuning, where the model is equipped with the external memory module and tasked with solving various reasoning problems.
The idea is that, in the self-supervised pretraining phase, the model would learn to compress and approximate language information. Then, in the reinforcement learning fine-tuning phase, the model would learn to use language to carry reasoning and computation in a precise and generalizable manner. In other words, it is as though the first phase consisted in learning the “machine” of intelligence, whereas the second phase consisted in operating it by learning the “program” of intelligence. In a way, this aligns with the notion presented by Mahowald et al. [71] that language and thought are distinct abilities that require different approaches. Thus, we could maybe say that in the first phase the model learns language, whereas in the second the model learns thought.
But this is just a rough idea and, naturally, it has its own set of challenges. What is the best way to implement the external memory module? Would it ever be practical to sequentially fine-tune something like a large language model with reinforcement learning, even with constant generation cost? What datasets and training objectives should be used in the fine-tuning phase? Would learning from text data alone using current machine learning methods be enough? And how could a model like this be used within a broader text-based agent framework, being able to use external tools in order to accomplish its goals?
At the end of the day, it only seems certain that efficiency and Turing completeness are important properties of models capable of general intelligence. This is a very complex and broad subject and no single article would be able to address all the related problems and possibilities. The approach presented here is thus mere speculation; only time will tell what such models will look like.
References
- D. Silver, A. Huang, C. Maddison, A. Guez, L. Sifre, G. Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis,
Mastering the game of go with deep neural networks and tree search,
Nature, vol. 529, no. 7587, pp. 484–489, 2016. [Online]. Available: https://doi.org/10.1038/nature16961 - D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, Y. Chen, T. Lillicrap, F. Hui, L. Sifre, G. Driessche, T. Graepel, and D. Hassabis,
Mastering the game of go without human knowledge,
Nature, vol. 550, no. 7676, pp. 354–359, 2017. [Online]. Available: https://doi.org/10.1038/nature24270 - A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, Zero-shot text-to-image generation, 2021. [Online]. Available: https://arxiv.org/pdf/2102.12092.pdf
- A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, Hierarchical text-conditional image generation with CLIP latents, 2022. [Online]. Available: https://arxiv.org/pdf/2204.06125.pdf
- R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, High-resolution image synthesis with latent diffusion models, 2021. [Online]. Available: https://arxiv.org/pdf/2112.10752.pdf
- OpenAI,
Introducing ChatGPT,
2022. [Online]. Available: https://openai.com/blog/chatgpt - L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, Training language models to follow instructions with human feedback, 2022. [Online]. Available: https://arxiv.org/pdf/2203.02155.pdf
- OpenAI, GPT-4 technical report, 2023. [Online]. Available: https://arxiv.org/pdf/2303.08774.pdf
- M. Forcada,
Neural networks: Automata and formal models of computation,
2002. [Online]. Available: https://www.dlsi.ua.es/~mlf/nnafmc/pbook.pdf - W. McCulloch and W. Pitts,
A logical calculus of the ideas immanent in nervous activity,
The bulletin of mathematical biophysics, vol. 5, no. 4, pp. 115–133, 1943. - S. Kleene,
Representation of events in nerve nets and finite automata,
in Automata studies. (AM-34), volume 34, C. Shannon and J. McCarthy, Eds. Princeton: Princeton University Press, 1956, pp. 3–42. - M. Minsky, Computation: Finite and infinite machines. Englewood Cliffs, NJ: Prentice-Hall, Inc., 1967.
- C. UTSA,
A logical neuron,
Website, [Online]. Available: https://marlin.life.utsa.edu/mcculloch-and-pitts.html - J. Elman,
Finding structure in time,
Cognitive Science, vol. 14, no. 2, pp. 179–211, 1990. [Online]. Available: https://doi.org/10.1016/0364-0213(90)90002-E - M. Steijvers and P. Grünwald,
A recurrent network that performs a context-sensitive prediction task,
In Proc. Proceedings of the eighteenth annual conference of the cognitive science society, 1996, p. 5. - F. Gers and E. Schmidhuber,
LSTM recurrent networks learn simple context-free and context-sensitive languages,
IEEE Transactions on Neural Networks, vol. 12, no. 6, pp. 1333–1340, 2001. [Online]. Available: https://doi.org/10.1109/72.963769 - S. Das, C. Giles, and G. Sun,
Learning context-free grammars: Capabilities and limitations of a recurrent neural network with an external stack memory,
In Proc. Proceedings of the fourteenth annual conference of cognitive science society, 1992, p. 14. - H. Siegelmann,
Recurrent neural networks and finite automata,
Computational Intelligence, vol. 12, no. 4, pp. 567–574, 1996. [Online]. Available: https://doi.org/10.1111/j.1467-8640.1996.tb00277.x - H. Siegelmann and E. Sontag,
On the computational power of neural nets,
In Proc. Proceedings of the fifth annual workshop on computational learning theory, 1992, pp. 440–449. [Online]. Available: https://doi.org/10.1145/130385.130432 - Y. Chen, S. Gilroy, A. Maletti, J. May, and K. Knight,
Recurrent neural networks as weighted language recognizers,
In Proc. Proceedings of the 2018 conference of the north american chapter of the association for computational linguistics: Human language technologies, volume 1 (long papers), 2018, pp. 2261–2271. [Online]. Available: https://aclanthology.org/N18-1205.pdf - G. Weiss, Y. Goldberg, and E. Yahav,
On the practical computational power of finite precision RNNs for language recognition,
In Proc. Proceedings of the 56th annual meeting of the association for computational linguistics (volume 2: Short papers), 2018, pp. 740–745. [Online]. Available: https://aclanthology.org/P18-2117.pdf - W. Merrill,
Sequential neural networks as automata,
In Proc. Proceedings of the workshop on deep learning and formal languages: Building bridges, 2019, pp. 1–13. [Online]. Available: https://aclanthology.org/W19-3901.pdf - G. Delétang, A. Ruoss, J. Grau-Moya, T. Genewein, L. Wenliang, E. Catt, C. Cundy, M. Hutter, S. Legg, J. Veness, and P. Ortega,
Neural networks and the chomsky hierarchy,
In Proc. The eleventh international conference on learning representations, 2023[Online]. Available: https://openreview.net/forum?id=WbxHAzkeQcn - K. Tran, A. Bisazza, and C. Monz,
The importance of being recurrent for modeling hierarchical structure,
In Proc. Proceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 4731–4736. [Online]. Available: https://aclanthology.org/D18-1503.pdf - S. Korsky and R. Berwick, On the computational power of RNNs, 2019. [Online]. Available: https://arxiv.org/pdf/1906.06349.pdf
- M. Suzgun, Y. Belinkov, S. Shieber, and S. Gehrmann,
LSTM networks can perform dynamic counting,
In Proc. Proceedings of the workshop on deep learning and formal languages: Building bridges, 2019, pp. 44–54. [Online]. Available: https://aclanthology.org/W19-3905.pdf - J. Ebrahimi, D. Gelda, and W. Zhang,
How can self-attention networks recognize dyck-n languages?,
In Proc. Findings of the association for computational linguistics: EMNLP 2020, 2020, pp. 4301–4306. [Online]. Available: https://aclanthology.org/2020.findings-emnlp.384.pdf - W. Merrill, G. Weiss, Y. Goldberg, R. Schwartz, N. Smith, and E. Yahav,
A formal hierarchy of RNN architectures,
In Proc. Proceedings of the 58th annual meeting of the association for computational linguistics, 2020, pp. 443–459. [Online]. Available: https://aclanthology.org/2020.acl-main.43.pdf - A. Zhang, Z. Lipton, M. Li, and A. Smola, Dive into deep learning. Cambridge University Press, 2023. [Online]. Available: https://D2L.ai
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, Ł. Kaiser, and I. Polosukhin,
Attention is all you need,
In Proc. Advances in neural information processing systems, 2017, vol. 30. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf - J. Pérez, J. Marinković, and P. Barceló,
On the turing completeness of modern neural network architectures,
In Proc. International conference on learning representations, 2019[Online]. Available: https://openreview.net/forum?id=HyGBdo0qFm - J. Pérez, P. Barceló, and J. Marinkovic,
Attention is turing-complete,
Journal of Machine Learning Research, vol. 22, no. 75, pp. 1–35, 2021. [Online]. Available: https://jmlr.org/papers/volume22/20-302/20-302.pdf - M. Hahn,
Theoretical limitations of self-attention in neural sequence models,
Transactions of the Association for Computational Linguistics, vol. 8, pp. 156–171, 2020. [Online]. Available: https://aclanthology.org/2020.tacl-1.11.pdf - D. Chiang and P. Cholak,
Overcoming a theoretical limitation of self-attention,
In Proc. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers), 2022, pp. 7654–7664. [Online]. Available: https://aclanthology.org/2022.acl-long.527.pdf - S. Yao, B. Peng, C. Papadimitriou, and K. Narasimhan,
Self-attention networks can process bounded hierarchical languages,
In Proc. Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: Long papers), 2021, pp. 3770–3785. [Online]. Available: https://aclanthology.org/2021.acl-long.292.pdf - S. Bhattamishra, K. Ahuja, and N. Goyal,
On the ability and limitations of transformers to recognize formal languages,
In Proc. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), 2020, pp. 7096–7116. [Online]. Available: https://aclanthology.org/2020.emnlp-main.576.pdf - G. Weiss, Y. Goldberg, and E. Yahav,
Thinking like transformers,
In Proc. Proceedings of the 38th international conference on machine learning, 2021, vol. 139, pp. 11080–11090. [Online]. Available: http://proceedings.mlr.press/v139/weiss21a/weiss21a.pdf - W. Merrill, A. Sabharwal, and N. Smith,
Saturated transformers are constant-depth threshold circuits,
Transactions of the Association for Computational Linguistics, vol. 10, pp. 843–856, 2022. [Online]. Available: https://aclanthology.org/2022.tacl-1.49.pdf - Y. Hao, D. Angluin, and R. Frank,
Formal language recognition by hard attention transformers: Perspectives from circuit complexity,
Transactions of the Association for Computational Linguistics, vol. 10, pp. 800–810, 2022. [Online]. Available: https://aclanthology.org/2022.tacl-1.46.pdf - W. Merrill and A. Sabharwal,
The parallelism tradeoff: Limitations of log-precision transformers,
Transactions of the Association for Computational Linguistics, vol. 11, pp. 531–545, 2023. [Online]. Available: https://aclanthology.org/2023.tacl-1.31.pdf - D. Chiang, P. Cholak, and A. Pillay,
Tighter bounds on the expressivity of transformer encoders,
In Proc. Proceedings of the 40th international conference on machine learning, 2023, vol. 202, pp. 5544–5562. [Online]. Available: https://proceedings.mlr.press/v202/chiang23a/chiang23a.pdf - W. Merrill and A. Sabharwal, A logic for expressing log-precision transformers, 2023. [Online]. Available: https://arxiv.org/pdf/2210.02671v4.pdf
- M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and L. Kaiser,
Universal transformers,
In Proc. International conference on learning representations, 2019[Online]. Available: https://openreview.net/forum?id=HyzdRiR9Y7 - J. Devlin, M. Chang, K. Lee, and K. Toutanova,
BERT: Pre-training of deep bidirectional transformers for language understanding,
In Proc. Proceedings of the 2019 conference of the north american chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186. [Online]. Available: https://aclanthology.org/N19-1423.pdf - T. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, Language models are few-shot learners, 2020. [Online]. Available: https://arxiv.org/pdf/2005.14165.pdf
- E. Grefenstette, K. Hermann, M. Suleyman, and P. Blunsom,
Learning to transduce with unbounded memory,
In Proc. Advances in neural information processing systems, 2015, vol. 28. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2015/file/b9d487a30398d42ecff55c228ed5652b-Paper.pdf - Y. Hao, W. Merrill, D. Angluin, R. Frank, N. Amsel, A. Benz, and S. Mendelsohn,
Context-free transductions with neural stacks,
In Proc. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP, 2018, pp. 306–315. [Online]. Available: https://aclanthology.org/W18-5433.pdf - A. Joulin and T. Mikolov, Inferring algorithmic patterns with stack-augmented recurrent nets, 2015. [Online]. Available: https://arxiv.org/pdf/1503.01007.pdf
- M. Suzgun, S. Gehrmann, Y. Belinkov, and S. Shieber, Memory-augmented recurrent neural networks can learn generalized dyck languages, 2019. [Online]. Available: https://arxiv.org/pdf/1911.03329.pdf
- B. DuSell and D. Chiang,
The surprising computational power of nondeterministic stack RNNs,
In Proc. The eleventh international conference on learning representations, 2023[Online]. Available: https://openreview.net/forum?id=o58JtGDs6y - A. Graves, G. Wayne, and I. Danihelka, Neural turing machines, 2014. [Online]. Available: https://arxiv.org/pdf/1410.5401.pdf
- J. Rae, J. Hunt, I. Danihelka, T. Harley, A. Senior, G. Wayne, A. Graves, and T. Lillicrap,
Scaling memory-augmented neural networks with sparse reads and writes,
In Proc. Advances in neural information processing systems, 2016, vol. 29. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2016/file/3fab5890d8113d0b5a4178201dc842ad-Paper.pdf - A. Graves, Adaptive computation time for recurrent neural networks, 2017. [Online]. Available: https://arxiv.org/pdf/1603.08983.pdf
- A. Banino, J. Balaguer, and C. Blundell, PonderNet: Learning to ponder, 2021. [Online]. Available: https://arxiv.org/pdf/2107.05407.pdf
- B. Amos and J. Kolter,
OptNet: Differentiable optimization as a layer in neural networks,
In Proc. Proceedings of the 34th international conference on machine learning, 2017, vol. 70, pp. 136–145. [Online]. Available: http://proceedings.mlr.press/v70/amos17a/amos17a.pdf - P. Wang, P. Donti, B. Wilder, and Z. Kolter,
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver,
In Proc. Proceedings of the 36th international conference on machine learning, 2019, vol. 97, pp. 6545–6554. [Online]. Available: http://proceedings.mlr.press/v97/wang19e/wang19e.pdf - A. Paulus, M. Rolinek, V. Musil, B. Amos, and G. Martius,
CombOptNet: Fit the right NP-hard problem by learning integer programming constraints,
In Proc. Proceedings of the 38th international conference on machine learning, 2021, vol. 139, pp. 8443–8453. [Online]. Available: http://proceedings.mlr.press/v139/paulus21a/paulus21a.pdf - Y. Du, S. Li, J. Tenenbaum, and I. Mordatch,
Learning iterative reasoning through energy minimization,
In Proc. Proceedings of the 39th international conference on machine learning, 2022, vol. 162, pp. 5570–5582. [Online]. Available: https://proceedings.mlr.press/v162/du22d/du22d.pdf - S. Bai, J. Kolter, and V. Koltun,
Deep equilibrium models,
In Proc. Advances in neural information processing systems, 2019, vol. 32. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2019/file/01386bd6d8e091c2ab4c7c7de644d37b-Paper.pdf - K. Liang, C. Anil, Y. Wu, and R. Grosse,
Out-of-distribution generalization with deep equilibrium models,
In Proc. Uncertainty and robustness in deep learning, ICML, 2021 - T. Kojima, S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa,
Large language models are zero-shot reasoners,
In Proc. Advances in neural information processing systems, 2022, vol. 35, pp. 22199–22213. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2022/file/8bb0d291acd4acf06ef112099c16f326-Paper-Conference.pdf - J. Wei, X. Wang, D. Schuurmans, M. Bosma, b. ichter, F. Xia, E. Chi, Q. Le, and D. Zhou,
Chain-of-thought prompting elicits reasoning in large language models,
In Proc. Advances in neural information processing systems, 2022, vol. 35, pp. 24824–24837. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf - S. Chung and H. Siegelmann,
Turing completeness of bounded-precision recurrent neural networks,
In Proc. Advances in neural information processing systems, 2021, vol. 34, pp. 28431–28441. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2021/file/ef452c63f81d0105dd4486f775adec81-Paper.pdf - A. Gu, T. Dao, S. Ermon, A. Rudra, and C. Ré, HiPPO: Recurrent memory with optimal polynomial projections, 2020. [Online]. Available: https://arxiv.org/pdf/2008.07669.pdf
- A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. Ré, Combining recurrent, convolutional, and continuous-time models with linear state-space layers, 2021. [Online]. Available: https://arxiv.org/pdf/2110.13985.pdf
- A. Gu, K. Goel, and C. Ré, Efficiently modeling long sequences with structured state spaces, 2022. [Online]. Available: https://arxiv.org/pdf/2111.00396.pdf
- J. Smith, A. Warrington, and S. Linderman,
Simplified state space layers for sequence modeling,
In Proc. The eleventh international conference on learning representations, 2023[Online]. Available: https://openreview.net/forum?id=Ai8Hw3AXqks - A. Orvieto, S. Smith, A. Gu, A. Fernando, C. Gulcehre, R. Pascanu, and S. De, Resurrecting recurrent neural networks for long sequences, 2023. [Online]. Available: https://arxiv.org/pdf/2303.06349.pdf
- M. Poli, S. Massaroli, E. Nguyen, D. Fu, T. Dao, S. Baccus, Y. Bengio, S. Ermon, and C. Ré, Hyena hierarchy: Towards larger convolutional language models, 2023. [Online]. Available: https://arxiv.org/pdf/2302.10866.pdf
- Y. Sun, L. Dong, S. Huang, S. Ma, Y. Xia, J. Xue, J. Wang, and F. Wei, Retentive network: A successor to transformer for large language models, 2023. [Online]. Available: https://arxiv.org/pdf/2307.08621.pdf
- K. Mahowald, A. Ivanova, I. Blank, N. Kanwisher, J. Tenenbaum, and E. Fedorenko, Dissociating language and thought in large language models: A cognitive perspective, 2023. [Online]. Available: https://arxiv.org/pdf/2301.06627.pdf
-
Feedback; recurrent connections. Interestingly, the idea of a recurrent network was present since the very inception of artificial neural networks in McCulloch and Pitts’s paper, although the modern recurrent neural networks that we know today would not be developed until the late 80s. ↩︎
-
The Parity language is the language of binary strings whose number of $1$s is even. ↩︎
-
The Dyck-$k$ language is the language of well-balanced parentheses, where $k$ indicates the number of types of parentheses. For instance,
({()})is a valid string in the Dyck-2 language, while({and({))are not. Due to its nature, this language is often used as a proxy for hierarchy understanding, which is considered essential for effective natural language processing. ↩︎ -
The Shuffle-Dyck-$k$ language is a Dyck-$k$ language where each type of bracket must be well-balanced while their relative order is unconstrained. For instance,
({)}is a valid string in the Shuffle-Dyck-2 language. ↩︎ -
For example, logspace-uniform $\textsf{TC}^0 \neq \textsf{NP}$. See Section 2 of Merrill and Sabharwal’s paper. ↩︎